Base de datos distribuida
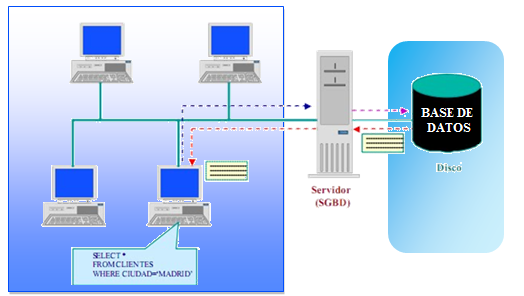
Una base de datos distribuida es un sistema de bases de datos que se encuentran ubicadas en diferentes nodos (servidores) conectados por una red, permitiendo la distribución de los datos entre los servidores. Esto mejora el rendimiento y disponibilidad del sistema, ya que permite a varios usuarios acceder a los mismos datos al mismo tiempo sin interferir los unos con los otros.
Las bases de datos distribuidas son una solución cada vez más común para los retos que plantea el almacenamiento de grandes volúmenes de datos. Estas estructuras permiten repartir los datos entre diferentes servidores, lo que mejora su rendimiento y disponibilidad. Lo que significa que varios usuarios pueden acceder a los mismos datos al mismo tiempo sin interferirse entre sí.
Seguidamente, examinaremos diferentes aspectos del uso de bases de datos distribuidas, comenzando por explorar los diferentes tipos existentes, seguido por sus estrategias de particionamiento y cómo implementarlas. Finalmente, profundizaremos en la consistencia y replicación en las bases de datos distribuidas para obtener un mejor rendimiento del sistema completo.
Tipos de bases de datos distribuidas
Existen cuatro tipos principales de bases de datos distribuidas:
- Bases de datos paralelas. Se trata de una base de datos que se ejecuta en varias computadoras conectadas entre sí para proporcionar mayor capacidad y rendimiento. Esta configuración se utiliza principalmente para optimizar la eficiencia y el rendimiento. Ya que una sola computadora no sería capaz de manejar la cantidad enorme de información almacenada en la base de datos.
- Bases de datos replicadas. Una base de datos replicada es aquella que se copia o replica en múltiples servidores para mejorar el rendimiento del sistema y garantizar la disponibilidad continua del servicio, incluso si hay fallas o problemas técnicos con uno o más servidores.
- Bases de datos particionadas. Esta es una forma avanzada y sofisticada de dividir las tablas o índices dentro del mismo servidor, permitiendo a los usuarios consultar los mismos resultados con mucha más rapidez. La partición puede ayudar a mejorar el rendimiento al reducir considerablemente el tiempo necesario para realizar operaciones complejas sobre grandes cantidades de información.
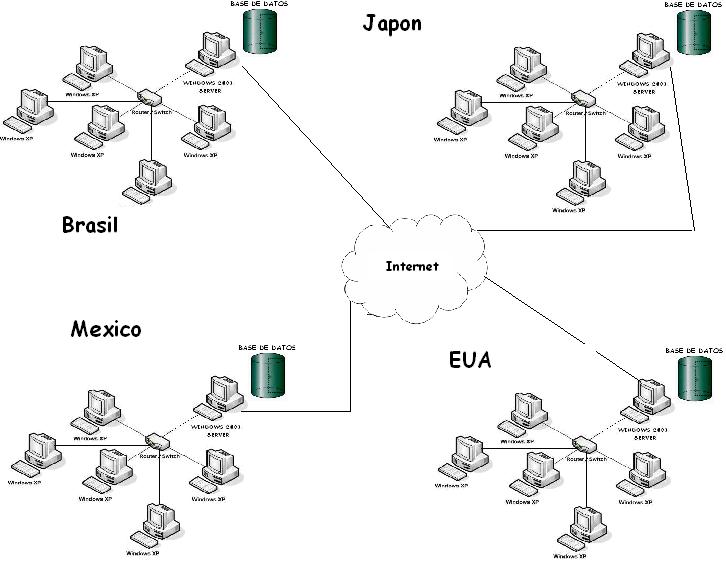
- Bases de datos globales. Están diseñadas para compartir información entre dos o más organizaciones separadas geográficamente, permitiendo que varias personas interactúen simultáneamente desde sus respectivas ubicaciones sin problemas ni retraso significativos en el tiempo real para obtener resultados uniformes y coherentes.
Estrategias de particionamiento en bases de datos distribuidas
El uso del particionamiento puede mejorar significativamente el rendimiento y la disponibilidad de las aplicaciones basadas en bases de datos distribuidas. Existen varias estrategias diferentes para particionar los datos, cada una con sus propias ventajas y desventajas:
- Particionamiento horizontal. El particionamiento horizontal divide los registros entre servidores basados en una clave común. Esto facilita redistribuir la carga entre varios servidores, lo que reduce el tiempo necesario para procesar consultas complejas.
- Particionamiento vertical. En este caso, los registros se dividen entre servidores basándose en un conjunto predefinido de columnas relacionadas. Esta estrategia es útil cuando hay muchas relaciones entre tablas. Ya que reduce la cantidad de consultas necesarias para recuperar los resultados deseados.
- Particionamiento por ubicación geográfica. Las empresas con usuarios o clientes repartidos por todo el mundo a menudo usan este tipo de particionamiento.
Cómo implementar una base de datos distribuida
Implementar una base de datos distribuida es un proceso mucho más complejo que implementar una base de datos local. Algunas consideraciones importantes son:
- Definir los requisitos de la aplicación. Una vez que se conocen los requisitos, se puede determinar el tipo de base de datos distribuida apropiada para el proyecto, ya sea en términos de escalabilidad, redundancia o fiabilidad.
- Seleccionar el sistema operativo y la tecnología adecuados. El sistema operativo para albergar la base de datos distribuida y las herramientas necesarias para administrarla deben ser seleccionadas teniendo en cuenta los requisitos del proyecto.
- Diseñar y configurar la arquitectura. La arquitectura debe ser diseñada para satisfacer los requisitos del proyecto, así como para garantizar la fiabilidad, escalabilidad y redundancia deseadas. Esta etapa incluye definir el número, ubicación y tamaño de los servidores necesarios, así como construir un plan maestro detallado sobre cómo conectar todos ellos entre sí.
- Instalación e implementación. Se instalan todas las herramientas necesarias e inicializan los servidores según lo previsto en el plan maestro anteriormente diseñado. Esta etapa implica la configuración adecuada del software correspondiente a cada servidor (motor de base de datos, servicios web) y su integración entre todos ellos para formular un clúster homogéneo eficiente y confiable.
- Pruebas exhaustivas. Una vez que todo está correctamente configurado, hay que realizar pruebas exhaustivas a nivel individual (por servidor) y global (para controlar el comportamiento del clúster) para certificar su funcionalidad antes del lanzamiento al mercado o puesta en producción.
Consistencia y replicación en bases de datos distribuidas
La consistencia y la replicación son conceptos clave en el diseño y la implementación de sistemas de bases de datos distribuidas. La consistencia se refiere a la propiedad que permite a los usuarios obtener siempre datos coherentes. En contraste, la replicación es el proceso mediante el cual se copian los datos en varios nodos para proporcionar redundancia, escalabilidad y disponibilidad. Estas dos características son fundamentales para garantizar una base de datos distribuida segura, confiable y eficiente.
La consistencia es crucial para mantener una base de datos distribuida consistente. Esto significa que todos los nodos deben tener acceso a las mismas versiones actualizadas de los datos. Los algoritmos de consenso permiten garantizar esta propiedad entre todos los nodos mediante mecanismos como el protocolo Paxos o Raft. Esto permite que todos los nodos estén sincronizados con respecto a su contenido y que cualquier cambio realizado por un usuario sea visible por otros usuarios sin demorarse demasiado tiempo.
Por otra parte, la replicación es necesaria para garantizar alta disponibilidad y tolerancia a fallas en una base de datos distribuida. Esto significa que si un nodo falla o cae temporalmente, otros nodos pueden asumir su lugar sin interrumpir el servicio. Se pueden utilizar diferentes estrategias para lograr este objetivo:
- Replicación completa. Todas las réplicas contienen exactamente las mismas informaciones.
- Replicación parcial. Las réplicas contienen diferentes partes del conjunto completo.
- Replicación activa-pasiva. Un conjunto primario contiene informaciones actualizadas mientras que otros servidores secundarios contienen réplicas antiguas.
- Replicación híbrida. Un grupo de servidores primarios tienen informaciones actualizadas mientras otros servidores secundarios tienen réplicas antiguas.

- Dual Boot - 07/07/2023
- DSL (Línea de suscriptor digital) - 07/07/2023
- Desnormalización de una base de datos - 07/07/2023